During my last term at Waterloo, I decided to explore my interest in machine learning and AI. Below are some of the experiments I played around with and some references to the papers I came across during my research.
Building a Perceptron
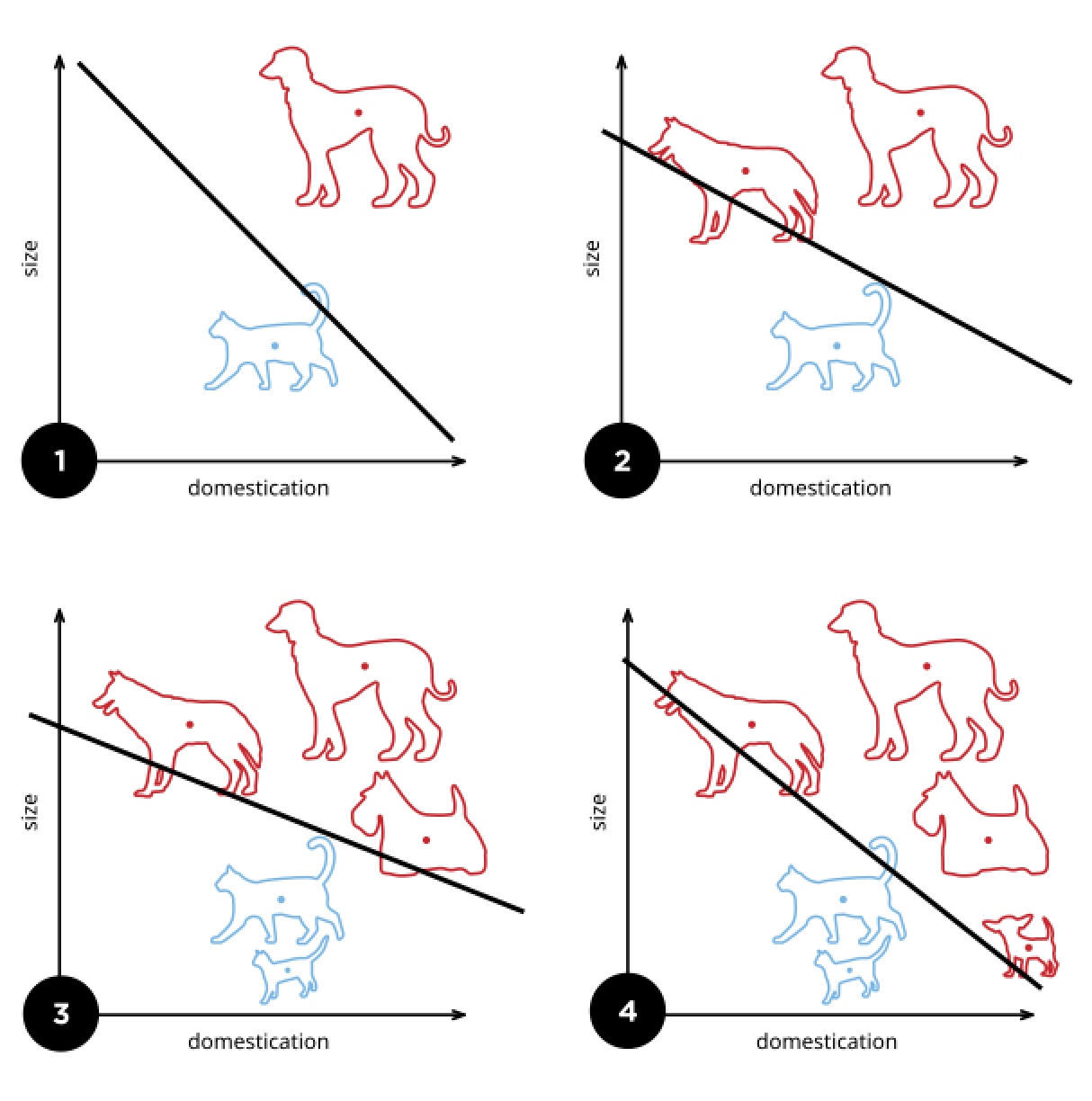
A perceptron linearly separates (classifies) a set of points based on a given characteristic1
Starting at the basics, one of the fundamental building blocks of neural networks is the perceptron. At its very fundamentals, it’s akin to a neural network with a single layer of weights and a bias term. Given a set of points, it's a linear classifier which can be used to classify points into two classes (and can be extended to multiple classes).
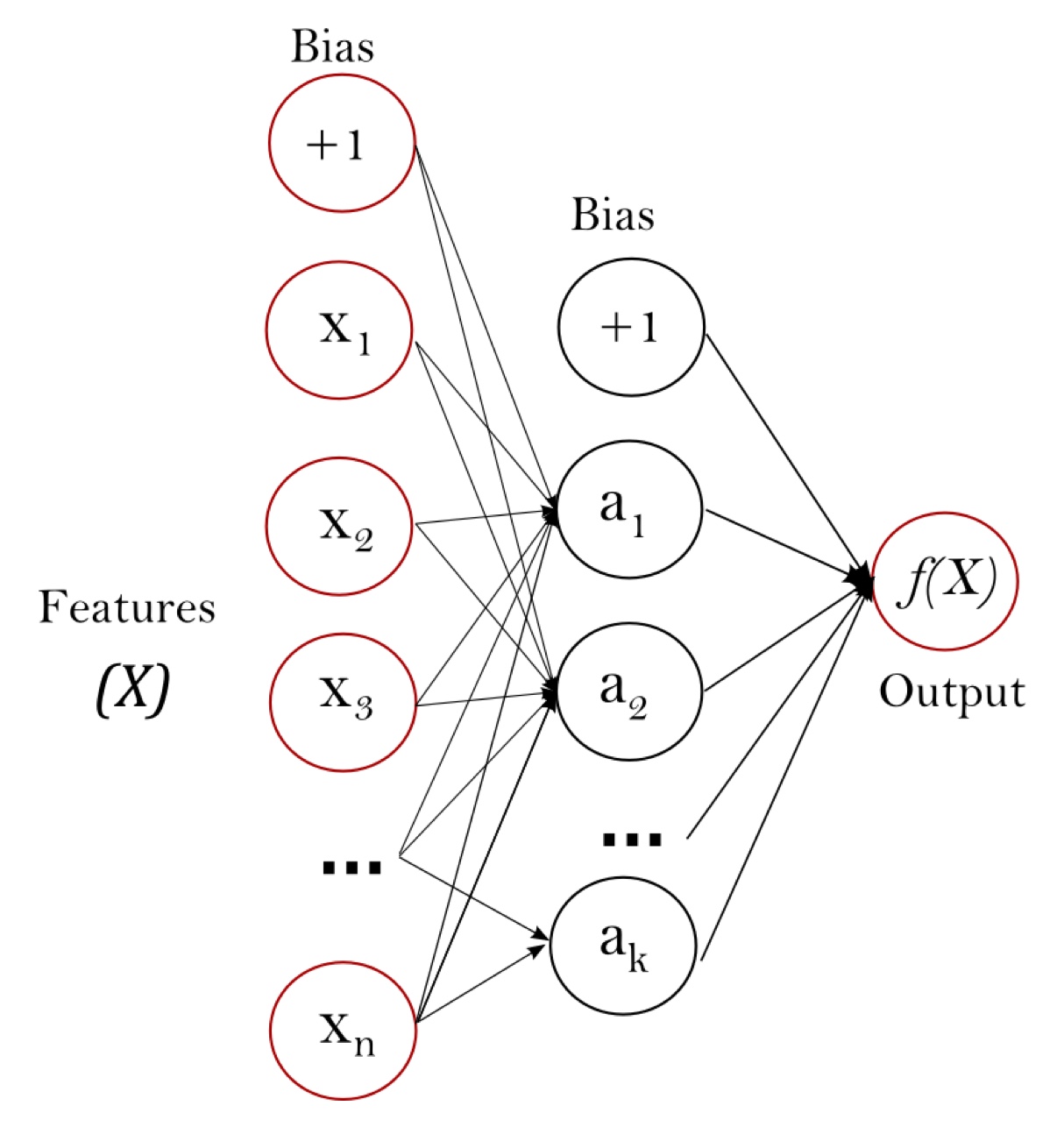
Multi-layer Perceptron with one hidden layer2
This is caveated by the fact that the data must be linearly separable. If it isn't, the perceptron will not converge and will not be able to classify. This is a limitation of the perceptron and is one of the reasons why it's not used in practice. However, it's a great starting point and is followed up by soft-margin SVMs (which introduce a slack variable to allow for misclassification) and neural networks with multiple layers.
Using the IRIS dataset, I was able to train a perceptron to classify the three classes of flowers.
Key Learnings
- The perceptron is very rudimentary but provides a good starting point to understand the basics of neural networks.
- The perceptron extends easily to hard-margin SVMs and as a corollary, soft-margin SVMs by introducing a slack variable.
- The perceptron is limited by the fact that it can only classify linearly separable data. This means that if the data is not linearly separable (which is the case with most real world data), the perceptron will not converge.
Building a Convolutional Neural Network
Following the perceptron, I explored the components of a convolutional neural network (CNN). CNNs are a type of neural network that are particularly well suited for image classification tasks. They are composed of convolution layers, pooling layers, and fully connected layers. They are particularly useful for image classification tasks as they are able to capture spatial hierarchies in images. By that I mean, they are able to capture features at different levels of abstraction using what is called a convolution kernel.
This is a very high level overview of CNNs and instead of re-inventing the wheel see 3Blue1Brown's video on convolutions which explains this process in a very intuitive way.
I also recommend reading the Stanford CS231n notes which are a great resource for understanding CNNs.
Included as well is the original paper by Simonyan and Zisserman (2014) of the AlexNet architecture which was the first CNN to win the ImageNet competition in 2012. Simonyan and Zisserman’s paper showed that 3x3 filters were particularly effective and optimal for CNNs and that deeper networks were able to capture more complex features as compared to shallow networks.
Using the CIFAR-10 dataset comprised of 10 classes of images, and splitting the data into training and testing sets, I was able to build a convolution class and train my own CNN model to classify images and test the accuracy of the model.

The ten classes as part of the CIFAR-10 dataset3
The hardest part of this process was building the convolution class from scratch. It's easy enough to use a library like TensorFlow or PyTorch and call Conv2d. Actually understanding how the convolution kernel is applied, how to pad the image, and how pooling layers work together provided me with a deeper understanding of how CNNs work. In the process of training the model, I computed the gradient with respect to a loss function following the process of stochastic gradient descent.
Key Learnings
- CNNs are particularly well suited for image classification tasks as the convolution layers can discern characteristics suited for image classification.
- Convolutions are only as good as the kernel used. The kernel is learned during the training process. Still, the size, number of filters, and stride are all hyperparameters that need to be tuned. Understanding how these hyperparameters affect the output of the convolution layer is crucial and necessary for building a good CNN model.
- There are various convolution models built on top of the basic CNN architecture. Like AlexNet, VGGNet, GoogLeNet, and ResNet. Each of these models has its own unique architecture and are suited for different tasks.
Transformers and Attention Mechanisms
Transformers are all the rage nowadays. They are particularly well suited for NLP tasks and have been shown to outperform RNNs and LSTMs on tasks like translation and language modeling4. The key to transformers is the attention mechanism which allows the model to focus on different parts of the input sequence. This is particularly useful for translation tasks as the model can focus on different parts of the input sentence and output the corresponding translation.
Again, there is no point in me re-inventing the wheel. 3Blue1Brown has a great video on the attention mechanisms and transformers.
I spent some time coding up the Multi-Head Attention mechanism with the (Q, K, V) queries, keys, and values. The trickiest part of this process was figuring out when to use self-attention heads and when to use cross-attention heads. It was also not easy when to join heads together and when to split them apart. Once I figured out the building blocks of the multi-head attention mechanism, I built an encoder block with a dropout layer, a skip connection with layer normalization, and a feed-forward neural network. I then built a decoder block with a similar architecture paying close attention to the masking of the input sequence and when to use self-attention and cross-attention heads. Finally, I built the transformer block itself, along with input masking and positional encoding of the input sequence.
Training the model was intensive even for a small sized dataset. It’s particularly challenging when GPU access is limited and batch sizes are small both issues I faced during the training process.
Key Learnings
- Transformers rely upon the logic of next word prediction. As is the case in training the model, we provide a sequence of words and ask it to predict the next word in the sequence. How does this occur when we wish to have supervised learning? We mask the next word and ask the model to predict the masked word. This has the downside of not being able to predict words unseen in its vocabulary/training set (see current workarounds to the in-domain problem).
- The attention mechanism is the key to the transformer's success.
- The transformer architecture is composed of an encoder and a decoder. The encoder is responsible for encoding the input sequence and the decoder is responsible for decoding the output sequence. The encoder and decoder themselves are composed of multiple transformer blocks which are composed of multi-head attention mechanisms and feed forward neural networks (see here for the actual architecture).
Generative Adversarial Networks (GANs)
This is by far the most exciting area of machine learning I have had a chance to work with from the ground up. GANs are a neural network made up of two key components: a generator and a discriminator.
The generator is responsible for generating fake data and the discriminator is responsible for distinguishing between real and fake data. The two work together to build a better model. They are trained simultaneously with the generator trying to fool the discriminator and the discriminator trying to distinguish between real and fake data. Ultimately, you end up with a generator that is able to generate data that is indistinguishable from real data (which can make for some really exciting results with relatively little training) and a discriminator that is able to distinguish between real and fake data.
While working with GANs I used the MNIST dataset which provides handwritten digits. I was able to train a GAN to generate fake handwritten digits that were indistinguishable from real handwritten digits.

Sample of handwritten digits from the MNIST dataset5
I built the generator using two linear layers and an output layer to match the dimensions of the images in the MNIST dataset. I built the discriminator in a similar fashion.
References
-
Goodspeed, Elizabeth. “Perceptron example.svg.” Wikimedia Commons, 13 May 2015, https://commons.wikimedia.org/wiki/File:Perceptron_example.svg. Creative Commons Attribution-Share Alike 4.0 International license.
-
“Multilayer Perceptron Network.” scikit-learn, https://scikit-learn.org/stable/_images/multilayerperceptron_network.png. Accessed 31 July 2024.
-
Krizhevsky, Alex. “CIFAR-10 dataset sample images.” University of Toronto, https://www.cs.toronto.edu/~kriz/cifar.html. Accessed 31 July 2024.
-
Vaswani, Ashish, et al. “Attention Is All You Need.” arXiv.org, 12 June 2017, https://arxiv.org/abs/1706.03762. Accessed 31 July 2024.
-
Suvanjanprasai. “MnistExamplesModified.png.” Wikimedia Commons, 24 May 2023, https://commons.wikimedia.org/wiki/File:MnistExamplesModified.png. Creative Commons Attribution-Share Alike 4.0 International license.
Note: The writing of this blog post was assisted by the use of GitHub Copilot.